
Ever written a loop where each iteration is independent of other iterations, like finding the value of pi by generating multiple random points inside a quadrant? If yes, then you perhaps realize that the loop executes the same task sequentially on the same core of the CPU while the other cores are underutilized when the task should be divided among them; after all, the result of each iteration is independent of the rest.
The solution to this problem is parallelization. In this article, I will walk you through the basics of one method of parallelization that doesn’t require any additional hardware like a GPU. We will use the Message Passing Interface(MPI), which can utilize different cores of a processor to run tasks parallelly and communicate the results among them.
Setup
You first need to install MPI on your machine. For windows users, you can install MPI from here. If you are on windows, you will have to add your MPI Installation Directory to your path variable. Linux users can install it using-
sudo apt update -y
sudo apt install -y mpi
sudo apt install mpi-default-binNext, you need to install mpi4py. Its installation is similar to any other python module( pip install mpi4py and so on). Once this is done, you are good to go. So, let’s begin with the “Hello World” of MPI.
Hello World
To run the code, open a terminal and cd to the directory of the python script and then execute mpirun -n numProcs python3 ScriptName.py. Note that for windows, you might have to replace mpirunwith mpiexec.Ensure that you change numProcsto the number of processors you want to use and ScriptNameto the name of your script. Note that I wrote my script in python3. Running the script with 4 processors produces the following output-
Processor 0 says Hello World
Processor 3 says Hello World
Processor 1 says Hello World
Processor 2 says Hello WorldSo, what happened? Well, each time you run the script, each of the 4 processors runs it separately. Hence, each of them prints the output on the console. You should note is that you can’t determine the order in which the output will appear from different processors. It depends on which processor sends the output first and other factors, and it’s unpredictable.
Communication with MPI
The most crucial feature in any parallelization is perhaps the ability of the individual parallel components to send data and communicate with each other. Here is a simple example of communication before we move on to doing something more serious with MPI-
Running the script with 4 processors produces the following output-
1 received from processor 1
2 received from processor 2
3 received from processor 3
6
Sent 1 to processor 0
Sent 2 to processor 0
Sent 3 to processor 0So, let’s break down what the script has done. It basically sent the rank of each processor to the 0th processor, which then calculated their sum(not a very useful application of MPI). The function send() has the following signature send(data, rank, tag). You can send any object as data to the processor ranked rank (0 in our case). The tag is a label for the data a processor has sent. All processors except processor 0 send their ranks to processor 0. Processor 0 runs a for loop and receives the data sent by each processor using the recv(source, tag) function. It’s important to note here that the recv() function blocks the code from going further until the data is received. For instance, if during the first iteration of the for loop by processor 0, processor 1 hasn’t sent any data, then processor 0 will wait for it before moving on to the next iteration. This is an example of blocking communication and can hinder the performance of your code.
Having understood the basics of communication, let’s apply it to a more serious problem in numerical methods in mathematics. We will calculate the integral of cos(x) with x ranging from 0 to π using Simpson’s 1/3 rule, which looks like this-
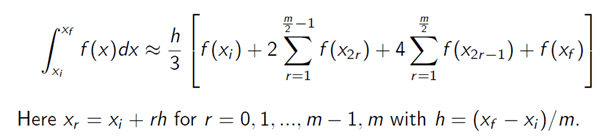
The idea of Simpson’s rule is that as you take larger and larger values of m, the sum on the right-hand side converges to the integral. Our task is to calculate that sum. There are 2 ways of doing it-
- You can just write a loop that sequentially calculates the sum.
- You can divide the integration range into smaller ranges, ask each processor to calculate the integral in the smaller range, and finally sum up the result. This works since
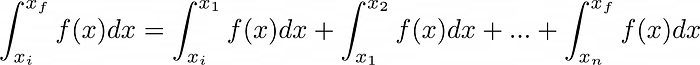
We will take the second approach using MPI.
Running the script with 4 processors produced the following output-
0.8768284552172905 sent by processor 1
Received 0.8768284552172905 from processor 1
Received -0.8768284552172895 from processor 2
-0.8768284552172895 sent by processor 2
Received -2.116851148460234 from processor 3
-2.116851148460234 sent by processor 3
Integral = -1.1546319456101628e-14Now, let’s break down the code. I have divided the range of integration into 4 sub-intervals. Each processor calculates the integral over its assigned sub-interval and passes it to processor 0, which then calculates the sum. Each processor uses 200 points in its assigned sub-interval for calculating the integral. You can see that the integral calculated by this script is very close to the actual value of the integral that is 0.
Speeding Things Up
I had mentioned earlier that using recv() makes the processor wait for the data from other processors. What if processor 3 sends the data before processor 1 does so? Processor 0 will still wait for processor 1 before using the data sent by processor 3. This slows down our code. So, the question is, can we do any better? It turns out that we can.
MPI offers a method called reduce() for this situation. Let’s take a look at a very trivial example-
Running it with 4 processors returns the following output-
Processor 2 generated random number 0.6449612839214244
Processor 3 generated random number 0.13580180096015093
Processor 1 generated random number 0.6150300627938315
Processor 0 generated random number 0.2527556536364435
1.648548801311850So, let’s break it down. Each processor generates a random number while running its own instance of the script. When any of the processors reaches the line sum = comm.reduce(rand, MPI.SUM), it passes rand to the MPI.SUM function, which is being run by processor 0(by default, it’s processor 0 that runs the function passed to reduce). The interesting thing about reduce() is that it receives a number from the processor that sends it first and adds it to the number passed by processor 0. This sum is stored. Next, it takes the number received from another processor and adds it to the sum stored earlier. This process goes on till all the numbers have been summed. Finally, the result is returned to processor 0. So, only processor 0 knows the value of the sum. If you try to print the value of sum from other processors, it will just print None.
You can pass any other function in place of MPI.SUM, but you need to take care of the peculiar way in which reduce() works. reduce() will take the data from 2 processors and apply the function you have given it, store the result, then take the data from another processor and call the function with this data and the result it had stored earlier. This process will go on till all the processors have sent their data.
Now, let’s have a look at a more serious application of reduce(). We are going to approximate the value of pi using a straightforward and well-known numerical technique. Suppose we have a square, and we draw a quadrant of a circle with a radius equal to the side of the square.
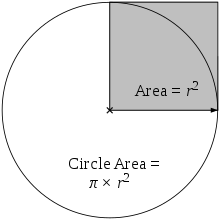
If we randomly pick a point with the square, what probability is the point lying inside the circle? You can intuitively guess that the probability is equal to the ratio of the areas(you can also prove it if you use the idea of independence of x and y co-ordinates and joint probability), i.e.,
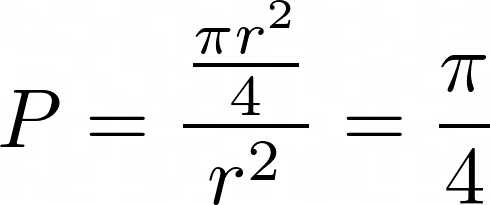
Now, suppose we pick a large number of points within the square and find the ratio of the number of points lying inside the circle to the total number of points. In that case, we expect the ratio to be approximately equal to π/4. So, let’s use this idea and our knowledge of MPI to approximate π using this method-
Running the script with 4 processors produces the following result-
3.140808So, let’s break this one down though I guess you already know what is happening in the code. We basically generate 1000000 points by dividing the task over 4 processors. Each processor calculates the number of points that lie inside the circle. In the end, processor 0 finds the total number of points inside the circle and then finds the value of π.
Note:- If you are confused with the if part, recall that the equation of a circle is x² + y²= 1 and any point lying inside the circle satisfies x² + y² < 1.
Conclusion and Beyond
So, I would stop here. I hope you have learned some of the basics of MPI. But this doesn’t end here. MPI has more to offer, and it would be an excellent idea to go through the mpi4py documentation if you want to learn more.
Happy Learning!